Sign-Agnostic Implicit Learning of Surface Self-Similarities for Shape Modeling and Reconstruction from Raw Point Clouds
Abstract
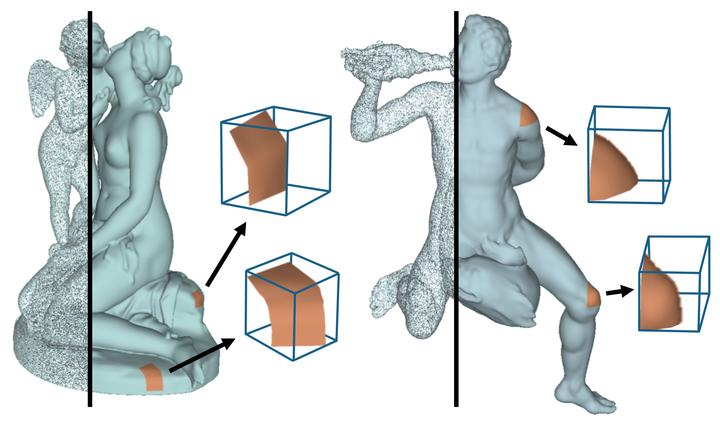
Shape modeling and reconstruction from raw point clouds of objects stand as a fundamental challenge in vision and graphics research. Classical methods consider analytic shape priors; however, their performance degraded when the scanned points deviate from the ideal conditions of cleanness and completeness. Important progress has been recently made by data-driven approaches, which learn global and/or local models of implicit surface representations from auxiliary sets of training shapes. Motivated from a universal phenomenon that self-similar shape patterns of local surface patches repeat across the entire surface of an object, we aim to push forward the data-driven strategies and propose to learn a local implicit surface network for a shared, adaptive modeling of the entire surface for a direct surface reconstruction from raw point cloud; we also enhance the leveraging of surface self-similarities by improving correlations among the optimized latent codes of individual surface patches. Given that orientations of raw points could be unavailable or noisy, we extend sign agnostic learning into our local implicit model, which enables our recovery of signed implicit fields of local surfaces from the unsigned inputs. We term our framework as Sign-Agnostic Implicit Learning of Surface Self-Similarities (SAIL-S3). With a global post-optimization of local sign flipping, SAIL-S3 is able to directly model raw, un-oriented point clouds and reconstruct high-quality object surfaces. Experiments show its superiority over existing methods.
Yuxin Wen
Senior Researcher
My research interests are in computer vision, computer graphics, and machine learning, with a recent focus on motion generation and multimodal alignment.